混同行列とその性能指標
混同行列は、分類問題においてモデルの性能を評価するために用いる正方行列であり、あるデータを分類したときに、その正解・不正解の数を整理しておく表のことである。正解、不正解を組み合わせると4パターンある。
分類問題におけるモデルの評価指標としては、
正解率 (accuracy):正解のレコード数をすべてのレコード数で割って求める
適合率・精度 (precision)
再現率 (recall) / 真陽性率 (true positive rate: TPR)(負例のrecall:偽陽性率 (false positive rate: FPR))
F値 (F-measure):適合率と再現率の調和平均
のようは指標がある。どの指標にも一長一短があり、様々な観点から、そのタスクに応じた最善の評価指標を選ぶ必要がある。
これらパターンや性能指標は、、https://analysis-navi.com/?p=550 (データ分析・AIの性能 データサイエンス情報局 2022年9月8日参照 より引用)でわかりやすく説明されている。
そのなかで、混同行列とその性能指標のまとめとして、下記のようにまとめられている。
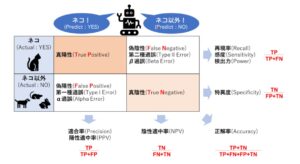
混同行列から直接読み取れる性能指標は上図で示したもので全てであるが、上の指標同士を組み合わせて、F値(F-measure)という指標もある。
F値とは、再現率と適合率の調和平均(「逆数の平均の逆数」)である。
F値 = (2 x recall x precision) / (recall + precision)
一般的に再現率と適合率はトレードオフの関係(「再現率が上がると適合率が下がる」「適合率が上がると再現率が下がる」という関係)にある。ります。
トレードオフとは、「再現率が上がると適合率が下がる」「適合率が上がると再現率が下がる」という関係にある。再現率と適合率を一方に偏らせずに均等に評価したい、という場合にF値が使われる。
以上
